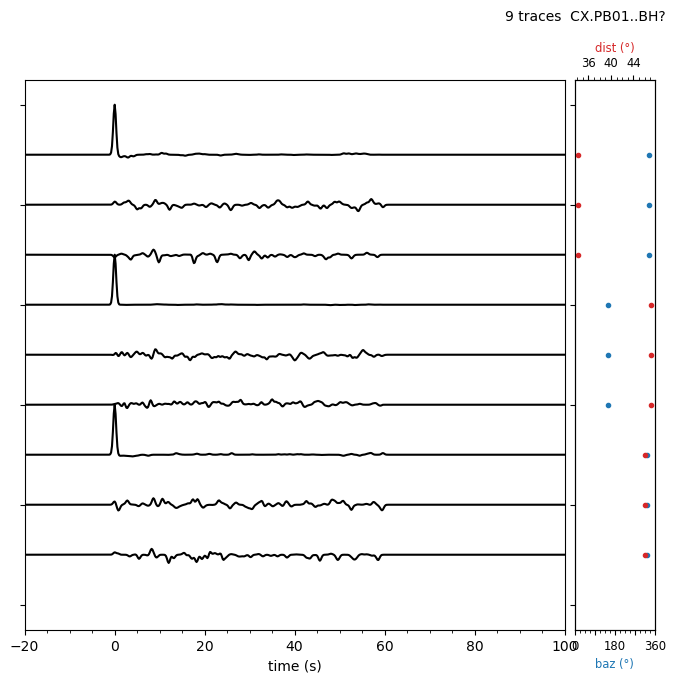
The length of the input data is 110s, but the RF result is plotted for 100s but only calculated for 50s, so until that delay time, spikes are added, but no more spikes afterwards, which is weird since I would at least expect the 660 to be visible in the data.
If I change the winsrc by myself, for example winsrc=(-5, 150-5,0) (following the code), The Data is deconvolved up to around 70s…so I wonder what is actually happening during the iterative deconvolution? Do I have to calculate twice the wished data length in order to observe the conversion I’d like to observe?
Any suggestions and help is highly appreciated! Thanks in advance,
Thea
Yes, it’s definitely an 'iterative' bug. Thanks for catching it! It’s coming from the parameter maxlag in the deconv_iterative() function. To be honest, I don’t remember why I had that set to maxlag=0.5*nfft but at the moment what that means is it’ll only try to add to the spike train for half the length of the trace, starting at the onset time. I guess one benefit of that is that in most cases, you’ll get super-clean zeros before the onset time, but if more than half a trace is before the onset time the outputs will look a bit strange.
Off the top of my head it seems like it would be fine to just set maxlag=nfft? For the test data it seems to work fine. Otherwise we could set maxlag based on trace length so the spike train is nonzero only from onset to the end.
Thank you guys so much for the fast responses and solutions!
Its working now. Although the command RF.deconvolve.deconvolve… is not working with the new package. But it’s running perfectly with RF.rf(deconvolve=‘iterative’…). So thanks a lot!
I think you mixed the module name and your variable name. The rf in rf.deconvolve.deconvolve() is the module. If you want to use the deconvolve method just do `stream.deconvolve()'.
I still have one open question considering the iterative deconvolution:
within the ZRT system, the deconvolved R component is showing an up- or downwards trend in the very beginning…I assume this is an artefact, probably because of the changed length?
I observed various spikes on the Z-component at later delay times, they are very tiny compared to the main spike at 0s, but still… Maybe I misunderstood the method, but I thought this was the trick of the iterative deconvolution, that the Z or L component has one spike with an amplitude of 1 at 0s.
I can reduce the spikes on the Z component by setting the minderr to 1, but this also reduces the peaks on the R and T component.
I’m not quite sure about your first question - could you post a figure?
For the second point, in theory, yes, the RF for the source component should be a spike of amplitude 1 at 0s lag, since you’re effectively trying to deconvolve it from itself. I think the reason you still see some non-zero values at other delay times is that the spikes used to build up the RF have a nonzero width, from the Gaussian filter.
I think you already have a sense of this from setting minderr to 1, but that parameter is the main control on how “messy,” or detailed, you want your spiky RFs to be. For each spike added to the RF, it calculates how much the error is reduced between the input response and the predicted response, and if that error reduction is below the threshold minderr it stops iterating. So, if you set minderr to a larger value, like 1, it’ll give you an RF with the major features (hopefully) picked out, and less noise, but for small minderr (and the default value is pretty small, I think) it has to work a bit harder to meet the threshold. So, for the source component, that spike at 0 lag gets added first, but since it’s not a delta function it isn’t quite perfect and the algorithm will continue to try adding spikes as long as the error reduction in each iteration is large enough.
thank you for your help and detailed answer, I do have a better understanding of the mechanisms behind the function now and especially of this minderr.
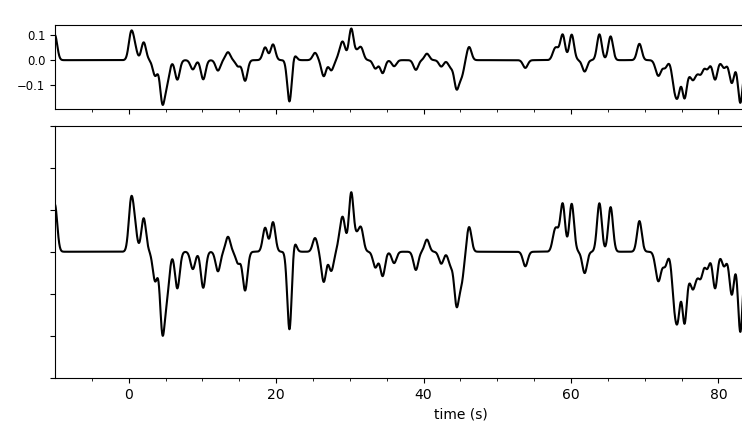
So, I’m attaching an example for the upward trend of the R-RF. It’s like the very first second, but I’d like to avoid any problems that are affecting the resulting RFs.
Thanks, I see what you mean. Yes, I think you’re right that it’s an artifact. In the patch, @trichter set maxlag so spikes are added to the RF from the onset time to the end of the trace. My guess is when the trace is shifted to put 0s lag at 0, a little bit from the end is wrapping around. Probably goes back, again, to the Gaussian filter and the width of the spikes - it looks like you’ve got ~half a spike or less aliased into the beginning there.
Hannah put it in a nutshell. The time shift wraps the end of the RF to the beginning. What you see is the half of a Gaussian, the other half is at the end. These points can be simply set to 0. Or even better, we can adapt maxlag once more.
I think the Z or L component should indeed be a spike, but only if you choose the whole trace as source. You also have to make sure to not use any taper, which is not the default. If you use the default, you will have some energy left at the end, where additional spikes will be added.
Should the default time window be changed to not use any tapering for iterative deconvolution?
I always tend to not use the whole Z/L trace as source, but I remember that at least for waterlevel deconvolution better results were obtained when the whole trace was used. (Therefore the different default windows.)
Oh, right, I forgot about the taper. Turning that off for the iterative deconvolution might be a good idea - it’s certainly not a necessary step.
Anyway, the aliasing can definitely be fixed with maxlag - if we take a few extra samples off to account for the width of the gaussian filter it should be ok.
I now refactored the whole beast again. See the changelog. The traces are now padded with zeros to completely get rid of any wrap-around effects. Therefore I see no need to mute the beginning of the trace anymore and turned it off. These wiggles before the onset are a feature . For convenience I added a kwarg mute_shift to get the muting back.